Table partitions
What are table partitions in ClickHouse?
Partitions group the data parts of a table in the MergeTree engine family into organized, logical units, which is a way of organizing data that is conceptually meaningful and aligned with specific criteria, such as time ranges, categories, or other key attributes. These logical units make data easier to manage, query, and optimize.
Partition By
Partitioning can be enabled when a table is initially defined via the PARTITION BY clause. This clause can contain a SQL expression on any columns, the results of which will define which partition a row belongs to.
To illustrate this, we enhance the What are table parts example table by adding a PARTITION BY toStartOfMonth(date) clause, which organizes the table`s data parts based on the months of property sales:
You can query this table in our ClickHouse SQL Playground.
Structure on disk
Whenever a set of rows is inserted into the table, instead of creating (at least) one single data part containing all the inserted rows (as described here), ClickHouse creates one new data part for each unique partition key value among the inserted rows:
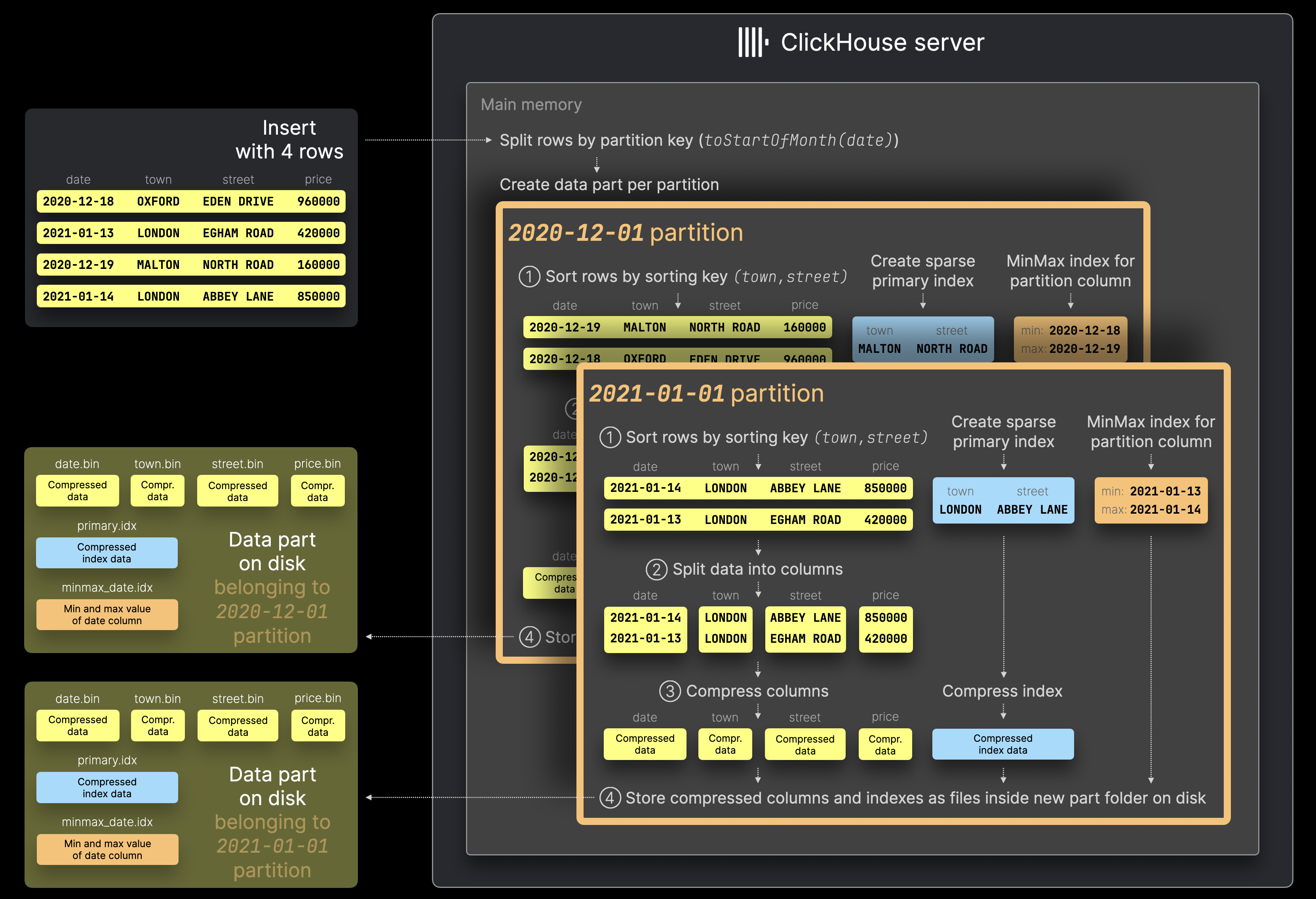
The ClickHouse server first splits the rows from the example insert with 4 rows sketched in the diagram above by their partition key value toStartOfMonth(date).
Then, for each identified partition, the rows are processed as usual by performing several sequential steps (① Sorting, ② Splitting into columns, ③ Compression, ④ Writing to Disk).
Note that with partitioning enabled, ClickHouse automatically creates MinMax indexes for each data part. These are simply files for each table column used in the partition key expression, containing the minimum and maximum values of that column within the data part.
Per partition merges
With partitioning enabled, ClickHouse only merges data parts within, but not across partitions. We sketch that for our example table from above:
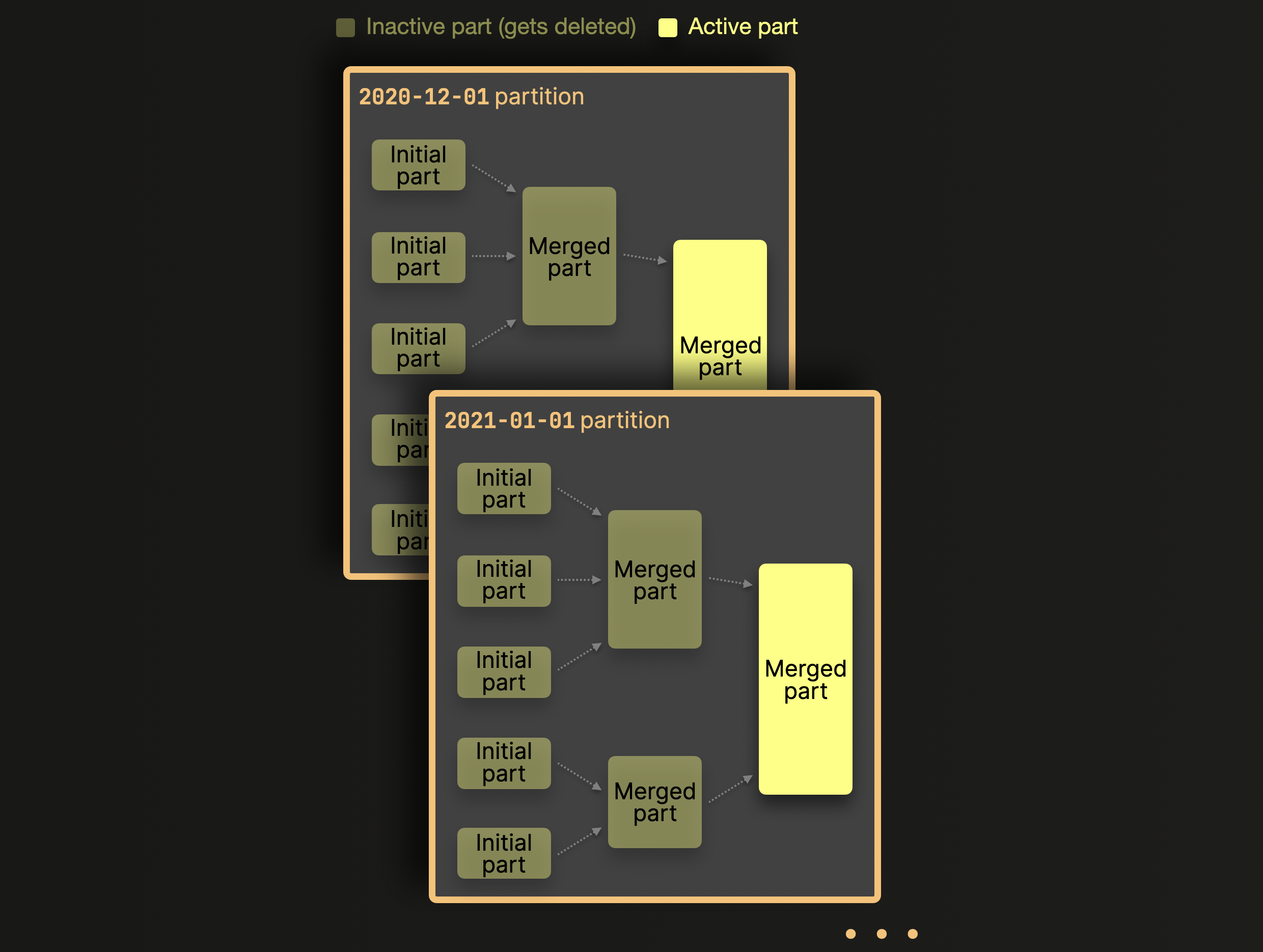
As sketched in the diagram above, parts belonging to different partitions are never merged. If a partition key with high cardinality is chosen, then parts spread across thousands of partitions will never be merge candidates - exceeding preconfigured limits and causing the dreaded Too many parts error. Addressing this problem is simple: choose a sensible partition key with cardinality under 1000..10000.
Monitoring partitions
You can query the list of all existing unique partitions of our example table by using the virtual column _partition_value:
Alternatively, ClickHouse tracks all parts and partitions of all tables in the system.parts system table, and the following query returns for our example table above the list of all partitions, plus the current number of active parts and the sum of rows in these parts per partition:
What are table partitions used for?
Data management
In ClickHouse, partitioning is primarily a data management feature. By organizing data logically based on a partition expression, each partition can be managed independently. For instance, the partitioning scheme in the example table above enables scenarios where only the last 12 months of data are retained in the main table by automatically removing older data using a TTL rule (see the added last row of the DDL statement):
Since the table is partitioned by toStartOfMonth(date), entire partitions (sets of table parts) that meet the TTL condition will be dropped, making the cleanup operation more efficient, without having to rewrite parts.
Similarly, instead of deleting old data, it can be automatically and efficiently moved to a more cost-effective storage tier:
Query optimization
Partitions can assist with query performance, but this depends heavily on the access patterns. If queries target only a few partitions (ideally one), performance can potentially improve. This is only typically useful if the partitioning key is not in the primary key and you are filtering by it, as shown in the example query below.
The query runs over our example table from above and calculates the highest price of all sold properties in London in December 2020 by filtering on both a column (date) used in the table's partition key and on a column (town) used in the table's primary key (and date is not part of the primary key).
ClickHouse processes that query by applying a sequence of pruning techniques to avoid evaluating irrelevant data:
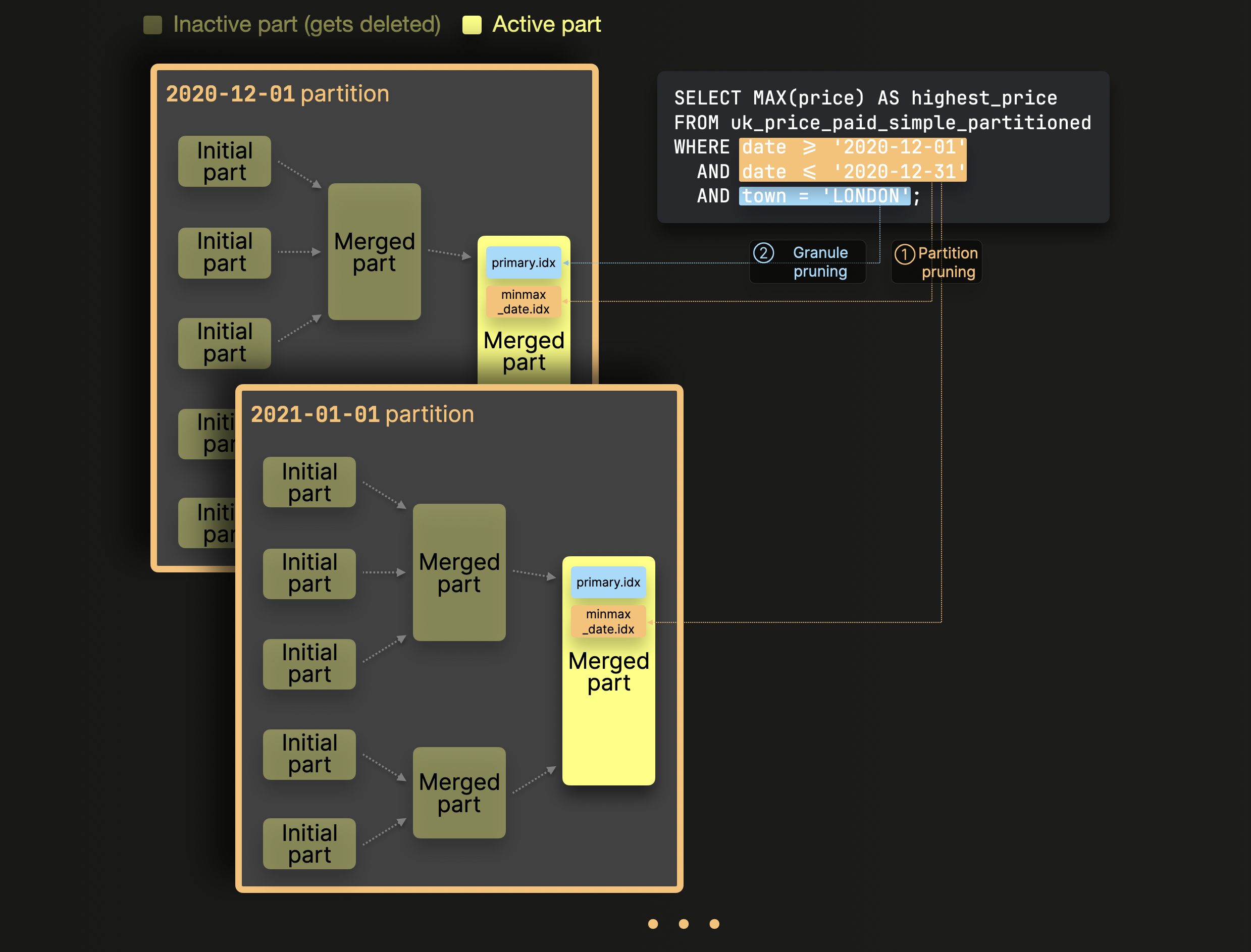
① Partition pruning: MinMax indexes are used to ignore whole partitions (sets of parts) that logically can't match the query's filter on columns used in the table's partition key.
② Granule pruning: For the remaining data parts after step ①, their primary index is used to ignore all granules (blocks of rows) that logically can't match the query's filter on columns used in the table's primary key.
We can observe these data pruning steps by inspecting the physical query execution plan for our example query from above via an EXPLAIN clause :
The output above shows:
① Partition pruning: Row 7 to 18 of the EXPLAIN output above show that ClickHouse first uses the date field's MinMax index to identify 11 out of 3257 existing granules (blocks of rows) stored in 1 out of 436 existing active data parts that contain rows matching the query's date filter.
② Granule pruning: Row 19 to 24 of the EXPLAIN output above indicate that ClickHouse then uses the primary index (created over the town-field) of the data part identified in step ① to
further reduce the number of granules (that contain rows potentially also matching the query's town filter) from 11 to 1. This is also reflected in the ClickHouse-client output that we printed further above for the query run:
Meaning that ClickHouse scanned and processed 1 granule (block of 8192 rows) in 6 milliseconds for calculating the query result.
Partitioning is primarily a data management feature
Be aware that querying across all partitions is typically slower than running the same query on a non-partitioned table.
With partitioning, the data is usually distributed across more data parts, which often leads to ClickHouse scanning and processing a larger volume of data.
We can demonstrate this by running the same query over both the What are table parts example table (without partitioning enabled), and our current example table from above (with partitioning enabled). Both tables contain the same data and number of rows:
However, the table with partitions enabled, has more active data parts, because, as mentioned above, ClickHouse only merges data parts within, but not across partitions:
As shown further above, the partitioned table uk_price_paid_simple_partitioned has 306 partitions, and therefore at least 306 active data parts. Whereas for our non-partitioned table uk_price_paid_simple all initial data parts could be merged into a single active part by background merges.
When we check the physical query execution plan with an EXPLAIN clause for our example query from above without the partition filter running over the partitioned table, we can see in row 19 and 20 of the output below that ClickHouse identified 671 out of 3257 existing granules (blocks of rows) spread over 431 out of 436 existing active data parts that potentially contain rows matching the query's filter, and therefore will be scanned and processed by the query engine:
The physical query execution plan for the same example query running over the table without partitions shows in row 11 and 12 of the output below that ClickHouse identified 241 out of 3083 existing blocks of rows within the table's single active data part that potentially contain rows matching the query's filter:
For running the query over the partitioned version of the table, ClickHouse scans and processes 671 blocks of rows (~ 5.5 million rows) in 90 milliseconds:
Whereas for running the query over the non-partitioned table, ClickHouse scans and processes 241 blocks (~ 2 million rows) of rows in 12 milliseconds: